Here at Dynamic Yield we are serving thousands of HTTP requests per second. Moving our serving services from EC2 to EKS required some tuning to ensure we could serve efficiently without losing any request. I summarized some tips and I hope it might help others with a smooth transition.
Overview
Kubernetes can decide to proactively replace pods (replicas) of our application, whenever:
- Kubernetes node is replaced (if the node is spot instance). If you have running pods on that node -- they will be terminated and new pods will start in another node instead.
- Kubernetes nodes scale-in. Pods in this node will be moved to a different node.
- Horizontal Pod Autoscaling (HPA) -- your service scale-in, thus, Kubernetes will terminate some of your replicas.
We want to ensure that during the pod's termination none of the requests will fail and all in-flight (currently being processed) requests will have enough time to respond before terminating a pod.
Upon termination, Kubernetes send SIGTERM signal to the pod's containers first, gives the application chance to gracefully stop, and few seconds after a SIGKILL signal kills all pod's containers. The time between those signals is our opportunity to ensure that the longest request is being processed, all connections are being closed, and we stop listening on the application's port.
Handle SIGTERM and readiness implementation
The first thing to notice is that in Kubernetes there are two probes: liveness and readiness. While liveness is relatively simple (return 200 to ensure our application is healthy/available), readiness is a bit different. Readiness probe determines whether our application can handle requests or not and responds accordingly:
```python from tornado.web import Application
class MyApplication(Application): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.ready_state = True
def sig_handler(application): logger.warning("SIGTERM received") application.ready_state = False tornado.ioloop.IOLoop.instance().add_timeout(60, close_conns)
class ReadinessHandler(RequestHandler): async def get(self): if cast(MyApplication, self.application).ready_state: self.set_status(200) else: self.set_status(503) await self.finish()
def main(): application = MyApplication([ (r"/readiness", ReadinessHandler), ]) server = tornado.httpserver.HTTPServer(application) server.listen(80) signal.signal(signal.SIGTERM, lambda: sig_handler(application)) tornado.ioloop.IOLoop.instance().start() ```
The snippet above is a simple Tornado's webserver application in Python. We defined a global "ready_state" that indicates whether the application can receive traffic or not. A new pod starts with a "ready_state" = True which means it can handle traffic immediately. Once the application receives SIGTERM this "ready_state" will be changed to False and the "/readiness" endpoint will return 503 (rather than 200). From now on, new requests won't be routed to this pod, and the pod needs to finish processing the in-flight requests and wait for SIGKILL signal from Kubernetes.
Side note: if your container's cmd is a bash script you must ensure that the signal is propagated to your application. Thus, it is useful to add a log while getting the signal to ensure it received. You can simulate it locally with:
``bash
docker kill --signal="SIGTERM" ``
Customize terminationGracePeriodSeconds
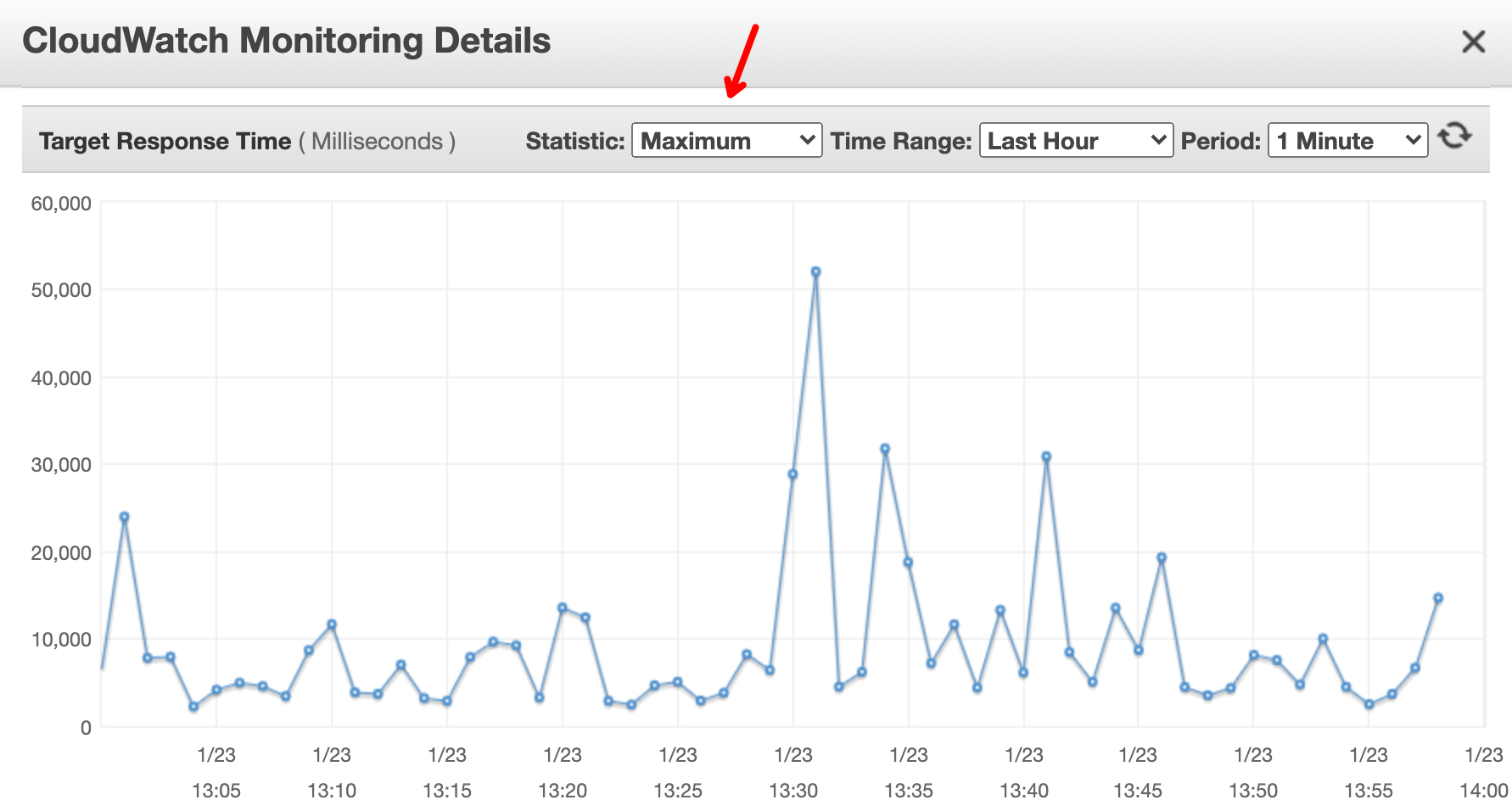
One way to configure the value is to find our longest request-time/latency. We can do that from our own application metrics (we are using both Prometheus & Graphite to measure those numbers) or in our AWS Load-Balancer metrics (CloudWatch):
{kind=link}
Note that we should check the maximum response time (and not the average) to ensure that the longest request (around 51 seconds in the image above) will be handled successfully.
Integration with AWS
We are using AWS ALB Ingress Controller to create an Application Load-Balancer for each Kubernetes ingress. We have a webserver with dozens of replicas (pods) and ingress that pass HTTP traffic to each pod. In addition, in the target-group associated with the ALB, you can see each one of those pods in the registered targets list. Each of those targets can be either healthy, unhealthy, draining, etc. Note that every resource (AWS Target-group/Kubernetes) has its own mechanism to decide whether traffic can be routed to a specific pod/target.
Since Kubernetes and AWS are not synchronized with their probes, here is a potential issue:
!Kubernetes readiness vs. target-group health-check
{kind=link}
Let's say we have a readiness probe configured with:
``
failureThreshold: 3
periodSeconds: 10
``
And target-group health checks defined with:
``
Unhealthy threshold: 3
Interval: 10
``
On a first impression it's hard to find what's wrong, but there's no guarantee that both mechanisms sample at the same time.
On one hand, if a pod won't answer 3 consecutive requests, Kubernetes ensure that the pod won't get traffic at 00:20. On the other hand. The same target will be considered as unhealthy at 00:29 -- so there are 9 seconds from 00:20-00:29 that the target will receive traffic (from target-group perspective) but Kubernetes won't allow this due to its own readiness mechanism. You will probably see ELB 5XXs in the Load Balancer's monitoring graphs.
A similar issue might happen when a new replica pod joins in and detected healthy by the AWS target-group but not yet by the Kubernetes readiness probe.
Readiness gates
To overcome the issue above, Kubernetes introduce readiness gates -- additional feedback on whether the pod can receive traffic or not. Adding the gates will solve the issue -- the pod will receive traffic only if both the target is healthy and readiness is true. Pod stop receives traffic as soon as one of readiness/readiness-gates will be false.
You can see information about the readiness gates with:
``
~ $ kubectl -n ``
Summary
We show some basic concepts to ensure a fluent transition to Kubernetes on top of AWS without losing even a single request! In the next post, I'll cover our custom HPA implementation for the same webserver.
In the following part, we'll discuss the challenges and the journey to scale.
This post was originally published in medium.